


Animaj leads the global media industry by creating and delivering premium 3D animation to families worldwide. Traditional animation, rooted in outdated processes since the early '90s, lags behind the fast-paced demands of today's digital economy.
Our innovation addresses the time-intensive nature of traditional animation, where each second can take hours or a week to produce.
Now, let's explore why traditional animation is so time-intensive.
In traditional animation, a 3D character is animated through a rig, composed of controllers, animating each part of his body and his face. A rig is a digital framework applied to a 3D model, featuring joints (representing the skeletal structure), control handles (onscreen manipulators used by animators to pose the rig), and constraints. Constraints establish rules for movement, enhancing control over the rig and facilitating the creation of lifelike and dynamic movements in the final animation. To animate a 3D character, the animator has to explicitly set the value of these controllers for many key poses and do the interpolation between these poses.
A wide proliferation of AI tools for humanoid content creation
Many technologies have been developed recently, allowing to quickly generate 3D motion. Motion capture (MoCap) techniques can now convert human actor movements into 3D animation, either from sensors, or, more recently, from video footage. Inspired by the many text-to-image models such as Dall-E or Imagen, some researchers also designed text-to-motion models, such as Human Motion Diffusion Model, allowing to generate a 3D motion from a single prompt. In an even more incredible way, some AI models can even generate a dance motion from music!
All these methods produce motions with a standard human morphology. Indeed, such deep learning models are trained on motion databases extracted from human-based videos, therefore extracting shapes with human proportions. Moreover, human shapes can be standardized in common formats, such as SMPL, making them easy to manipulate with deep learning models.
However, our IPs are not composed of standard humans but of iconic characters with unique shapes that deviate from the standard human body proportions.
Therefore, we need to find a way to transfer the motion generated on the human shapes to our specific characters.
Animaj motion transfer model
Method: Mesh-based motion transfer
A 3D character is composed of two primary elements: a mesh and a skeleton. The skeleton defines the key moving bones, such as the hips, arms, legs… The mesh serves as the envelope of the body, rendered with texture and lightning. Traditional motion transfer methods rely on the characters' skeletons: they involve mapping the two skeletons of the characters and directly transferring the animation from one skeleton to another.
However this approach isn’t adapted for the characters in children’s animation. Firstly, the main skeleton structures might differ considerably, complicating the process of skeleton mapping. Secondly, these characters have very distinctive volumes, and transferring motions using the skeletons may lead to pronounced issues of mesh self-penetration.
Therefore we develop a motion transfer method based on the meshes of the characters. The model will do the motion transfer pose by pose. This model takes as input the mesh of the source character in T-pose and in its animated pose and the mesh of the target character. From these meshes, the model predicts the mesh of the target character in the animated pose.
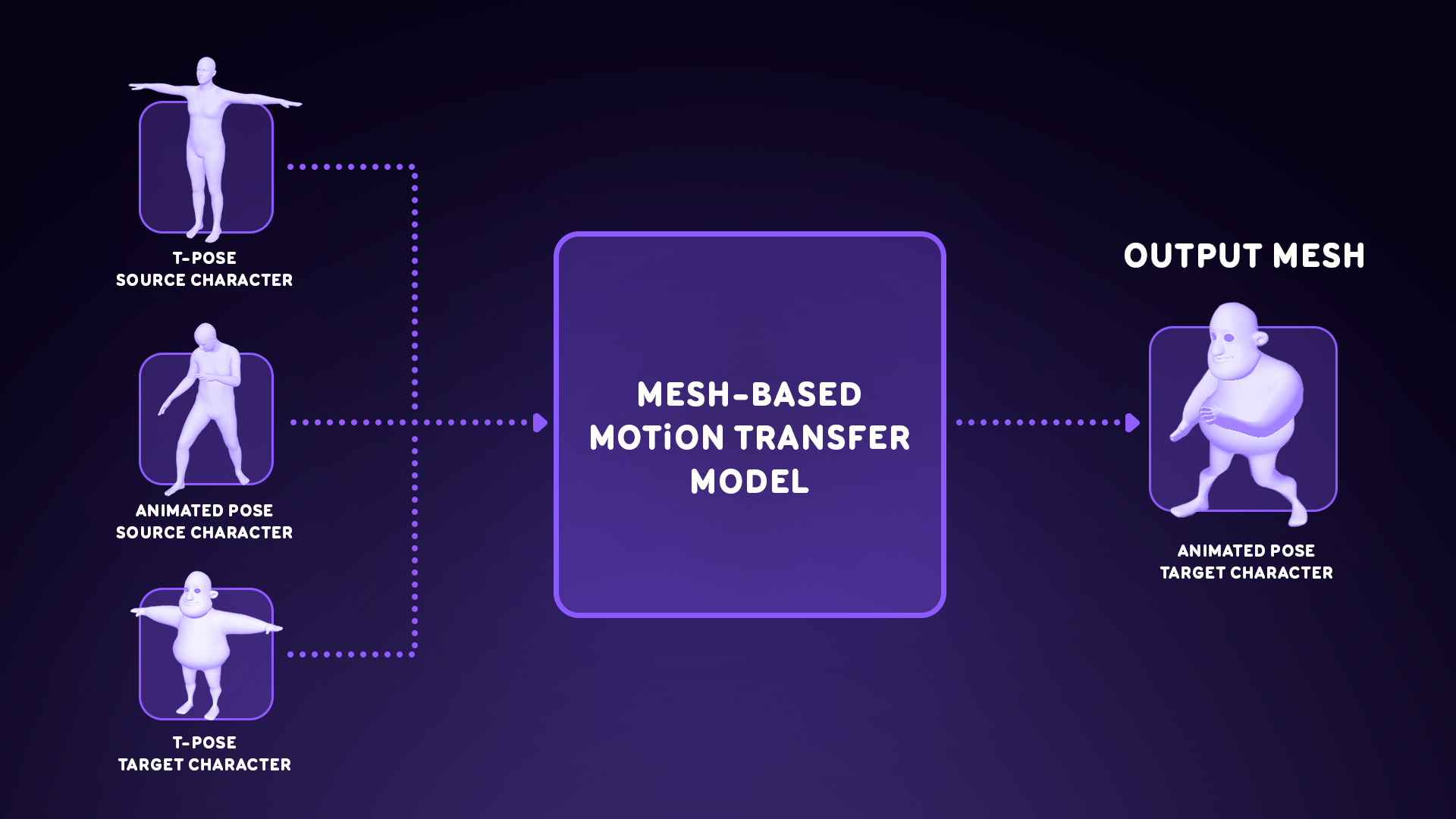
Another advantage of using meshes lies in the fact that they can be encoded in a standardized binary format: a graph. Indeed, a character mesh can be seen as a combination of vertices and edges. This enables us to utilize Graph Neural Networks (GNN) models for encoding the meshes.
Training
For each IP, we train a motion transfer model on the characters of this IP in order to learn the details and specificities of each character.
Dataset creation
To specialize pose transfer models for our characters, we initially considered extracting data from past animations. However, this approach posed a limitation as our dataset would solely comprise unpaired poses, given the distinct animations of each character in a scene. To address this, we complemented our dataset by directly manipulating characters to generate paired poses. This involved creating a range of motion for each character through a simple gym routine:
- Determine the maximum range for a particular motion by rotating a subset of body joints in a specific direction until the initial occurrence of self-penetration.
- Generating a fixed number of evenly spaced intermediate poses within this range.
- Defining pairs between characters based on body joint angles relative to each character's maximal range: position at X% between a character T-pose and the maximal motion for this character will be paired across characters.
Although this process allows for generating a large number of paired poses, it requires a 3D animation software, such as Maya, and consumes significant time and CPU resources, and cannot be run online during training. Instead, we generate a large dataset of paired poses offline and store it for training purposes.
Training losses
Throughout the training, the model performs the motion transfer on the characters and predicts the animated pose of the target character. Several losses are applied on this generated mesh, each one related to one of our objectives:
- Fidelity to the input motion: the primary goal is to replicate the same motion on the target character. To maintain fidelity to the original motion, the main straightforward loss is a vertex-based distance loss between the generated mesh and the ground-truth mesh, when paired data are available. In the case of unpaired data, a cycle of motion transfer is performed, transferring from source to target characters, and back to the source. The distance loss is then applied between the final generated source mesh and the original source mesh.
- Fidelity to the target character: recognizability of our iconic characters is a key element of motion transfer, and their mesh should remain free from deformation. To preserve fidelity to the target character, we added an edge length loss to the mesh, ensuring a constant distance between neighboring vertices of the mesh.
- Self-penetration: as the volumes of the characters are different, the model should adapt the motion to prevent self-penetration of meshes. We used a self-penetration loss penalizing the vertices that intersect with the mesh itself.
- Ground penetration: feet extending below the ground is a common issue of mesh generation. We implemented a ground penetration loss, penalizing vertices situated below the floor.
Rig reintegration
The output from our model comprises a series of meshes, each corresponding to a frame of animation, capturing the motion. However, manipulating a mesh is not feasible due to constraints on the body, where the movement of individual faces within a joint should occur collectively rather than independently. This makes adjustments, such as moving a full arm, impractical. Consequently, to make our model's output adaptable for animators, we perform a crucial step we call "rig reintegration", wherein we apply the generated motion to the character's rig, enabling flexibility for further adjustments. Additionally, during this step, we generate a file formatted to be seamlessly integrated - if needed - with standard animation software such as Maya, Unity, Blender, or Unreal Engine.
To apply the motion depicted in the sequence of meshes to the rig, we use the meshes to impose physical constraints on the rig, compelling it to mirror the movement. This is akin to using each mesh as a mold for the rig. Through this process, we achieve precise replication of the motion generated by our model.
Results
We show qualitative results obtained by using our solution.
Conclusion
At Animaj, scaling the production of our episodes is of paramount importance. To meet the demands of digital platforms, we've harnessed the power of AI. With our solution, we've significantly cut down the animation time for digital-first content by 85%. Our central motion transfer tool plays a pivotal role by enabling us to seamlessly manage various inputs, including existing motions, motion capture, and those generated from text, audio, or visual content.
We would like to express our gratitude to Christophe Petit, Tristan Giandoriggio and Remi Gamiette from the animation studio The Beast Makers for playing a crucial role in extracting data from animation files and converting our model outputs back to the animation software.

.svg)







.jpg)
