


More and more ML teams are reaching for Rust when Python hits its limits. Here's Animaj's hands-on journey — from profiling a slow pipeline to a 600x performance breakthrough.
In 2024, we shipped the first version of our Sketch-to-motion workflow. Naturally, one of our first moves was to profile the full pipeline to find where time was being spent.
In short, the pipeline works like this: a hand-drawn sketch goes in, a neural network predicts a vectorized representation of the character's rig, and a post-processing step converts that vector back into a usable pose. We expected the neural network inference to be the bottleneck, but the profiler told us a different story. Indeed, we already worked hard to optimize the inference but we didn’t focus on the post-processing step at all, and it was dominating the runtime.
We needed to make it run faster. After evaluating other options, we landed where much of the ecosystem is converging: Rust. Its compiled performance rivals C, its memory safety eliminates entire classes of bugs, and bridging it with Python is easy. We're far from alone in this choice: Pydantic, Polars, Hugging Face's Tokenizers, Ruff, uv, … the list of "Python" tools actually powered by Rust keeps growing.
Why Rust?
This shift happens because standard Python performance is often insufficient for heavy data manipulation. While each new version of Python is faster than the previous one and Python 3.13 brought exciting improvements like the JIT compiler and the "Free-threaded" GIL-free mode, it is still very far from the performance of a compiled language.
Some solutions exist to compile Python to native code. The most well-known are probably Cython and Numba. However, they both come with significant trade-offs: non-standard types that break tooling and unpredictable performance gains.
The alternative is to replace Python's hot paths entirely by calling into another language via bindings. However, binding Python to another garbage-collected language is a challenge. Both runtimes try to manage the same memory, leading to problems such as memory leaks, double frees, and use-after-frees, or requiring heavy, slow bridges to synchronize reference counting. This rules out most languages, leaving only those without a garbage collector as viable candidates: C, C++, Rust, and Zig.
C or C++ are notoriously difficult to write correctly, largely due to the burden of manual memory management and its associated pitfalls. Rust offers the same low-level performance while providing memory safety by default. Thanks to PyO3, Maturin and uv, bridging it with Python has become seamless. Zig could be an alternative in the future, but the language and its Python binding ecosystem are not quite mature enough yet.
Nearly two years ago, we evaluated Rust with a small-scale experiment. The Motion-to-motion transfer project required us to detect self-penetration (when a 3D character's arm passes through its own torso, for example). This test needed to run thousands of times per frame, making performance critical. We integrated the Parry collision detection library by wrapping this Rust crate with PyO3. The binding itself was remarkably minimal: one function converts a point cloud into a convex polyhedron, and another computes the signed distance between two convex polyhedrons.
That simplicity was encouraging. A small, focused wrapper had been enough to create a high-performance collision detection library that we can call easily from Python. After this initial success, we continued reaching for Rust whenever performance demanded it. In the rest of this post, we'll walk through another concrete use case.
Scaling Vectorization 600x
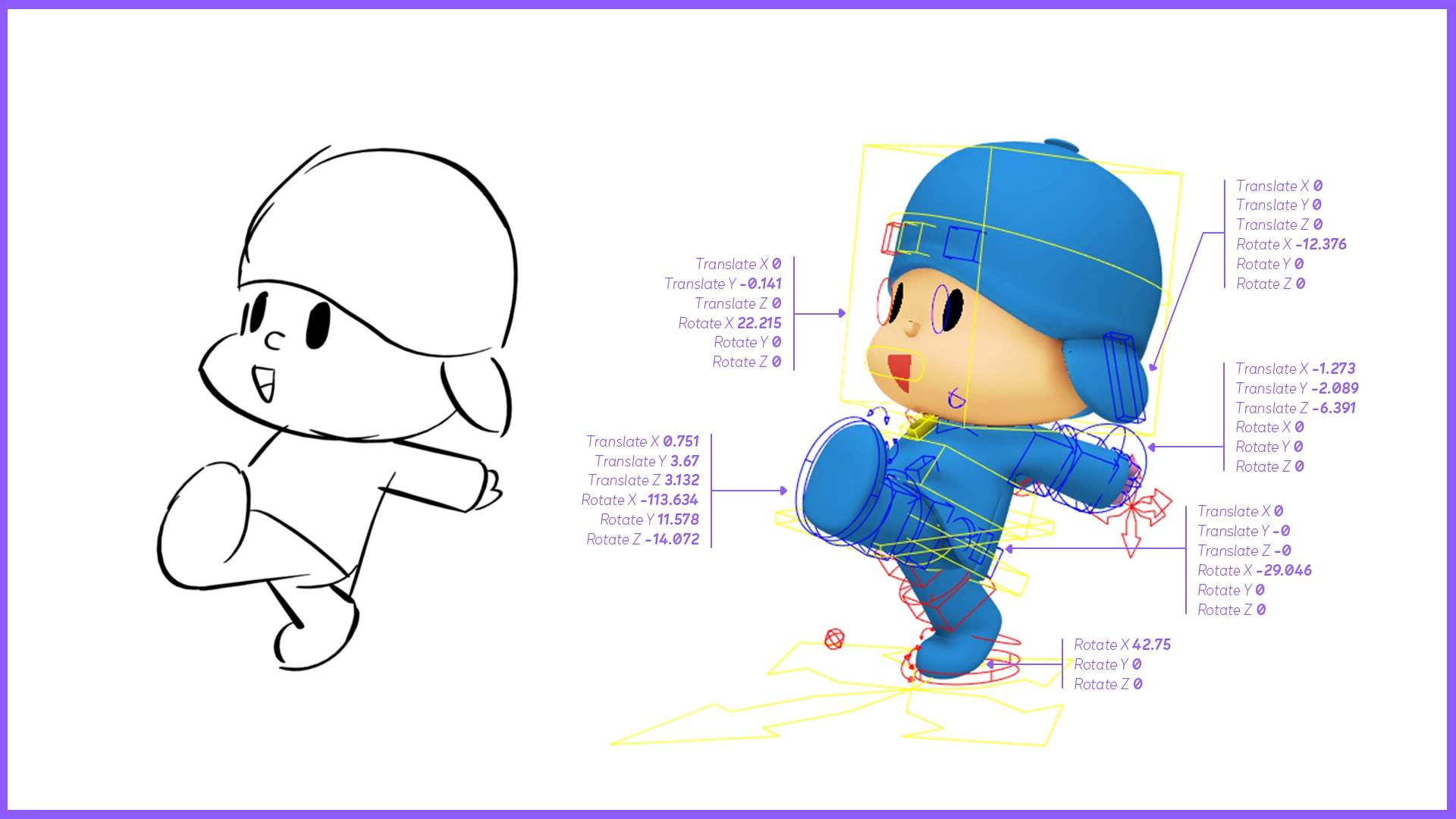
Our sketch-to-pose models predict character rig controller values (translation, rotation, scale) from a drawing. To interact with 3D software, these values are encoded as a nested Python dictionary. For instance:
rig_controller_values = {
"left_hand": {
"translateX": -0.8296477794647217,
...
},
...
}
Some controllers have all 9 transformations enabled (3 translations, 3 rotations, 3 scales), while others have only a few, or even a single one.
This format is not suitable for model training as-is. We need to normalize the values and change the rotation representation (Euler angles are not a continuous representation, meaning two rotations that are close in 3D space can have very different Euler values, which makes learning unstable). We therefore need to vectorize this structure before it can be used in our training pipeline.
In practice, for each character we define a set of TrainableControllers: a mapping between a subset of controller names and their allowed transformations, along with additional metadata such as normalization coefficients. In Python, the definition looks roughly like this:
trainable_controllers: list[TrainableController]
@dataclass
class TrainableController:
controller_name: str
transformations: list[Translation|Rotation1D|Rotation3D|Scale]
Using this, we define the two conversion functions rig-to-vec and vec-to-rig.
The rig-to-vec function is only called when preparing data for training. The vec-to-rig, on the other hand, is used in production to convert the neural network’s output into a format that can be read in Maya or Blender. This distinction matters, because any inefficiency in vec-to-rig has a direct impact on inference latency.
Before shipping our first model to production, we profiled the inference pipeline using Python's cProfile and SnakeViz. The chart we obtained looked like this:

(If you're not familiar with this type of chart: rectangle widths are proportional to the relative duration of each function. Each row represents a deeper level of nesting. Here, run_inference_pipeline calls predict_step, which calls vec_to_rig_wrapper, and so on.)
We discovered that the vec_to_rig function was consuming more than 60% of total inference time! It was time to rewrite it in Rust.
Naive Rust rewrite
At its core, vec_to_rig could be summarized as a large match statement inside two nested loops:
def vec_to_rig(
trainable_controllers: list[TrainableController],
vec: torch.Tensor,
):
rig = {}
current_vec_idx = 0
for controller in trainable_controllers:
for transformation in controller.transformations:
match transformation:
case Rotation1D(axis=axis):
rig[controller.name][f"rotate{axis}"] = atan2([...])
case Rotation3D():
euler_angles = rot6d_to_euler(vec[current_vec_idx:])
for axis, angle in zip("XYZ", euler_angles):
rig[controller.name][f"rotate{axis}"] = angle
...
current_vec_idx += size
return rig
Both the data structures and the conversion logic translate naturally to Rust. The trainable controllers become:
pub struct TrainableControllers {
// Each entry is a (controller_name, list of transform types) pair
values: Vec<(String, Vec<Transform>)>,
}
pub enum Transform {
Translation(Translation),
Rotation3D(Rotation3D),
Rotation1D(Rotation1D),
Scale(Scale),
}
The vec_to_rig function follows the same structure as the Python version, using HashMap (Rust’s equivalent of Python dictionary) to build the output.
When we benchmarked this first Rust implementation against the Python one, the Rust code was 35x faster (measured by taking the median of 1000 runs, on the same EC2 instance type we used in production).
This was a good start, but could we optimise even more?
Removing IntoPyObjectConverter
To understand how the time was spent, we profiled the code using perf on Linux, and hotspot to visualize the result. (all subsequent profiles in this section use the same setup).

One thing really stands out: the “py03:impl_::wrap::IntoPyObjectConverter” accounts for ~40% of total execution time. This function is responsible for converting the Rust HashMap into a Python dictionary. Although the two data structures are conceptually similar, their internal implementations differ significantly, and the conversion is expensive.
This suggested a clear path forward: instead of building a Rust HashMap and paying the conversion cost at the end, we could work directly with PyDict, a data structure exposed by PyO3 that lets you create and mutate Python dictionaries from within Rust. This eliminated the IntoPyObjectConverter overhead entirely.
The new code was 70x faster than the Python equivalent
Going Further with Rust Procedural Macro
We profiled the new PyDict-based implementation.

As expected, no more IntoPyObjectConverter!
Digging deeper into the profiling results, however, we found a new bottleneck: a high volume of calls to both setters and getters (get_item and contains). This was a consequence of how the code mutated nested PyDict structures: before appending data to an inner dict, it had to check whether that dict already existed, create it if not, and then retrieve a mutable reference to it. A lot of bookkeeping and hash computation for every single call.
One option would have been to rethink the design of the code and use Rust tricks to cache references to inner dicts and avoid the repeated lookups. Instead, we took a different approach that solved these issues more thoroughly: Rust Procedural Macros.
The key insight was that the trainable controllers list is defined once at the start of a project and never changes. This meant we could read the YAML configuration file at compile time and generate a fully optimized, specialized vec_to_rig function for each character. The macro unrolls the loops and resolves all conditions at compile time, producing flat, straight-line conversion code. The benefits are significant:
- No more runtime data checks
- No more borrow checker friction — since the code is unrolled, each PyDict can be owned, mutated freely, and released cleanly
- Fewer instructions to execute overall
- No branch misprediction
In terms of code, a procedural macro is a function that takes a stream of tokens as input and returns another stream of tokens. In our case, it looks like this:
#[proc_macro]
pub fn rig_to_vec_macro(input: TokenStream) -> TokenStream {
let (yaml_file, vec) = parse_macro_input!(input);
// create the trainable_controller structure at compile time
let tc = create_trainable_controller_from_yaml(&yaml_file).unwrap();
// vector id, used and incremented at compile time
let mut i: usize = 0;
// token stream that will form the output of this macro
let mut output_token_streams = Vec::new();
// Create the top-level rig_dict at runtime
output_token_streams.push(quote! {
let mut rig_dict = PyDict::new(py);
});
// for loop executed at compile time
for (controller_name, transforms) in tc.get_values().iter() {
// controller_values dict created at runtime
token_streams.push(quote! {
let mut controller_values = PyDict::new(py);
});
// this loop also runs at compile time
for transform in transforms {
// as does this match statement
match transform {
Transform::Translation(translation) => {
for axis in &translation.axes {
[...]
// controller_values.set_item called at runtime
token_streams.push(quote! {
let value = &#vec[#i] * #scale + #center;
controller_values.set_item(#attr_name, AttributeValue::Float(value))?;
});
i += 1;
}
}
[...]
}
}
// rig_dict populated at runtime
token_streams.push(quote! {
rig_dict.set_item(#controller_name, controller_values)?;
});
}
quote! {
{
#(#token_streams)*
rig_dict
}
}.into()
}
Using the cargo expand command, we can inspect the intermediate Rust code generated by the macro (comments added for clarity)
pub fn vec_to_rig_pocoyo<'py>(
py: Python<'py>,
vec: PyReadonlyArray1<'_, Float>,
) -> PyResult<Bound<'py, PyDict>> {
let vec = vec.as_slice()?
let ret = {
let mut rig_dict = PyDict::new(py);
// first controller
let mut controller_values = PyDict::new(py);
let value = &b[0usize] * 25f32 + 0f32;
controller_values.set_item("translateX", AttributeValue::Float(value))?;
let value = &b[1usize] * 25f32 + 0f32;
controller_values.set_item("translateY", AttributeValue::Float(value))?;
let value = &b[2usize] * 25f32 + 0f32;
controller_values.set_item("translateZ", AttributeValue::Float(value))?;
rig_dict.set_item("x_main_CTRL", controller_values)?;
// another controller
let mut controller_values = PyDict::new(py);
let value = &b[28usize] * 0.9f32 + 1f32;
controller_values.set_item("scaleX", AttributeValue::Float(value))?;
rig_dict.set_item("l_armIKUpper_CTRL", controller_values)?;
// and another one
let mut controller_values = PyDict::new(py);
let value = &b[29usize] * 7f32 + 0f32;
controller_values.set_item("translateX", AttributeValue::Float(value))?;
let value = &b[30usize] * 7f32 + 0f32;
controller_values.set_item("translateY", AttributeValue::Float(value))?;
let value = &b[31usize] * 7f32 + 0f32;
controller_values.set_item("translateZ", AttributeValue::Float(value))?;
rig_dict.set_item("l_armIK_CTRL", controller_values)?;
No loops, no conditionals. Just direct, flat assignments.
This new implementation is 110x faster than the original Python.
Bypassing PyDict: direct JSON output
Time for another round of profiling. With the PyObject conversion gone and the macro eliminating runtime branching, the picture had changed significantly. But the profile still showed a clear bottleneck: the PyDict setter calls were now the dominant cost.
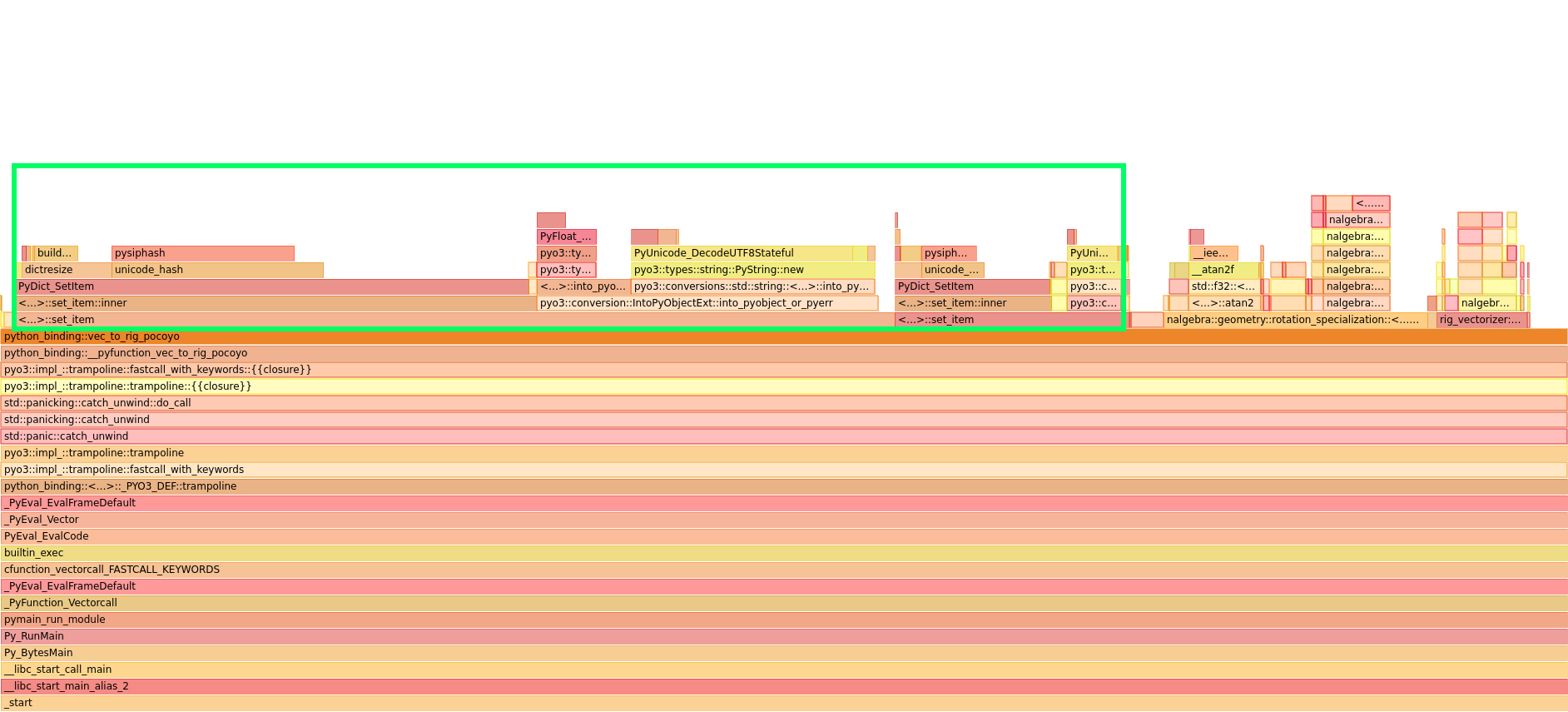
If we absolutely had to return a Python dictionary, there would be no way around this. Every key-value pair requires allocating a Python object, going through PyO3's type conversion layer, and inserting into a hash table managed by the Python runtime. But did we actually need to return a dict?
Looking at the inference call, vec_to_rig returns a dictionary that is immediately serialized to JSON and sent to the client over a web API. So what if we skipped the dictionary entirely and returned the JSON string directly from Rust?
We tested several approaches. Building a HashMap and serializing it with serde_json was cleaner to write but still incurred allocation overhead. What turned out to be the fastest approach was working at the string level directly: pre-allocating a string buffer of the right capacity and writing the JSON output into it field by field.
This works particularly well in combination with our procedural macro. Since the structure of the output is fully known at compile time, the macro can compute a tight upper bound on the output size from the trainable controller definitions and emit a single String::with_capacity(...) call, leading to a single heap allocation. At runtime, the function just fills in the numeric values
The result: 200x faster than the original Python implementation.
from JSON to MessagePack
One last round of profiling.

The PyDict overhead was gone, the loops were unrolled, and we were writing directly to a pre-allocated string buffer. And yet the profile still had something to say: core::fmt::Write::write_fmt was now consuming 71% of execution time.
This function is called every time a float number is converted to a string representation. It turns out that correctly converting an IEEE 754 floating-point number to its shortest accurate decimal representation is a genuinely hard problem that needs to be solved for every single value in the output. As long as we were producing JSON, there was no way around it.
But did we have to produce JSON? Looking at the full data flow, the JSON string was sent over a web API to a 3D software client, which then immediately parsed it back into floats. We were doing float → string → float on every inference call, paying the formatting cost on the Rust side and the parsing cost on the client side. Switching to a binary format would eliminate both.
We replaced the JSON output with MessagePack, a compact binary serialization format that encodes floats directly in their binary representation. The change was relatively small: instead of writing formatted strings into a buffer, we write binary-encoded values using rmp::encode
The code was now 600x faster than the original Python implementation.

This last profile showed that all remaining time was spent inside our main logic, computing our custom transformations.
The final model inference profile looks like this:

The vec-to-rig used to be a function consuming 60% of inference time. Now it’s invisible.
To be fair, the naive Rust rewrite alone (35x faster) would have been sufficient for most use cases. But digging deeper into the profiling revealed much more about the internals of Rust and Python, and proved to be an incredible learning journey.
The broader lesson isn't specific to Rust or this function: profile first, question and understand what you find, then optimize and repeat.
A summary of all the runs gave this chart:

With:
- Python: the baseline implementation
- Rust (HashMap): the naive rewrite using HashMap
- Rust (PyDict): the first optimisation with replacing the HashMap by PyDict
- Macro (HashMap/PyDict): both versions written with the proc-macro
- Python (JSON): the baseline implementation, plus the JSON conversion
- Rust (JSON): the naive Rust rewrite, serializing the HashMap before returning
- Macro (JSON): the proc-macro Rust code serializing the HashMap before returning
- Macro (Direct JSON): the proc-macro Rust code writing directly the JSON string
- Macro (Direct MessagePack): the proc-macro Rust code writing directly the MessagePack structure
Conclusion
Rust is a language that fits naturally alongside Python. It requires some initial setup, but the barrier has never been lower thanks to great tooling (PyO3, Maturin and uv). The result is a stack where Python keeps research agile, and Rust ensures that agility never comes at the cost of production performance.
The key to get the most out of this is profiling (probably one of the most underrated skills in ML engineering). In an era where coding agents can generate Rust bindings in minutes, the real leverage is knowing where to apply them.
The work we presented here is not specific to Animaj. The methodology is the same regardless of the project: don't assume you know where the bottlenecks are. Profile first, then optimize.

.svg)









